[new:30/03/2014]Cela fait un petit moment que je n'avais pas parler de .NET et de C# pourtant sources inépuisables de plaisirs… Aujourd'hui je vous propose de découvrir un petit sentier peu emprunté, celui de la programmation Orientée Aspect avec la classe RealProxy. Toute une aventure vous verrez que vous ne le regretterez pas !
Programmation Orientée Aspect
Je vais commencer pour donner la définition de Wikipédia, juste pour le plaisir de lire un galimatias jargonneux comme notre belle profession sait en produire :
« La programmation orientée aspect (POA, en anglais aspect-oriented programming ou AOP) est un paradigme de programmation qui permet de traiter séparément les préoccupations transversales (en anglais, cross-cutting concerns), qui relèvent souvent de la technique (aspect en anglais), des préoccupations métier, qui constituent le cœur d'une application1. Un exemple classique d'utilisation est la journalisation, mais certains principes architecturaux ou modèles de conception peuvent être implémentés à l'aide de ce paradigme de programmation, comme l'inversion de contrôle (en anglais, inversion of control ou IOC). »
Nous voilà bien avancé ! Ca a dû être écrit par un ingénieur employé dans l'administration genre sécu ou SNCF (ce n'est plus vraiment une administration mais l'esprit est bien resté intact comme les ex PTT !).
Maintenant qu'on a bien rigolé sur la prose spécieuse et incompréhensible qui se veut savante, en vrai c'est quoi la POA ? et en quoi c'est utile surtout ?
En gros le but est toujours de séparer les choses. Comme MVVM sépare l'UI du code, la POA sépare les « préoccupations » des différentes couches d'une application pour les traiter à part. Mais je ne vais pas jargonner à mon tour, je vous renvoie à Wikipédia et à un papier du JDN qui reste lisible : « Expliquez moi… la programmation Orientée Aspecté ».
Ici je préfère en général partir du concret pour aider le lecteur à comprendre plutôt qu'adopter une attitude digne d'un amphi dans lequel au milieu tout en bas un gars débite son flot de parole sans se soucier des pauvres étudiants qui tout autour dans les gradins essayent de comprendre…
Ce qu'il faut retenir c'est qu'un logiciel bien architecturé est conçu en couches distinctes qui s'intéressent à des aspects particuliers, par exemple la séparation DAL / BOL / UI. Le but étant que ces couches communiquent le moins possible ou alors par des canaux bien formalisés et faciles à tracer.
Supposons maintenant que nous possédions une telle application, bien décomposées en couches ayant chacune ses responsabilités clairement définies et que cet ensemble soit bien écrit et maintenable. Ajoutons le grain de sel qui va tout mettre par terre : le client, votre patron, peu importe qui, vous-même peut-être, quelqu'un décide :
- Qu'il faut ajouter un système d'authentification utilisé avant toute requête en lecture et en écriture ;
- Ou bien qu'il faut effectuer certaines nouvelles validations sur les données avant leur écriture ;
- Ou encore qu'il est nécessaire d'instrumentaliser tout le code pour faire un audit de toutes les méthodes utilisées ;
- Ou dans le même esprit que l'application doit journaliser certains évènements ;
- Ou par exemple encore mesurer le temps d'exécution de certaines parties de code pour en vérifier les performances en exploitation ;
- Etc… Vous pouvez imaginer un million d'autres demandes de ce genre.
Toutes ces nouvelles conditions vont nécessiter beaucoup de travail et, pire, de la duplication de code. Vous devrez ajouter le même code ou le même type de code un peu partout sans rien oublier. Le désastre arrivera très vite : les oublis s'ajouteront aux bugs, aux erreurs de copier / coller, le tout augmenter par la redondance du code en violation totale du sacro-saint principe DRY, c'est-à-dire « Don't Repeat Yoursef » (ne vous répétez pas !).
Toutes les modifications évoquées plus haut réclament des modifications massives du code ce qui, au minimum sera couteux en temps de travail.
Face à de telles situations on peut se prendre à rêver et se dire « et si le compilateur pouvait ajouter pour moi ce code répétitif et systématique ? ». On pourrait même envisager une option du type « ajouter tel morceau de code à toutes les méthodes dont le nom commence par Get* » pourquoi pas… Ce n'est une demande idiote.
La mauvaise nouvelle c'est que C# même en version 5 ne propose rien de tout cela, mais ni Java ni Objective-C et encore moins cette plaisanterie qu'est JavaScript.
Mais il y a une bonne nouvelle… C'est qu'un modèle de programmation ressemblant à cela existe déjà, ça s'appelle justement la Programmation Orientée Aspect. Elle permet de séparer les aspects qui traversent les limites des objets ou des couches de l'application. L'un de nos exemples ci-dessus, la journalisation de certains évènements, est un bon exemple puisque qu'un Log de ce type n'appartiendra à aucune couche en particulier et concernera certainement toutes celles en place.
Dans le jargon qu'on a pu lire plus haut ou ailleurs, c'est ce qu'on appelle une « préoccupation transversale ». Mais maintenant on comprend ce que cela veut dire ! C'est la différence entre le jargon de base et les explications de Dot.Blog J
Si on reprend ce que Wikipedia dit de la POA, « un paradigme de programmation qui vise à accroître la modularité en permettant la séparation des coupes transversales de préoccupations. » On comprend alors que la POA traite des fonctionnalités qui concernent plusieurs parties de l'application et qui les sépare de la base de l'application afin d'améliorer la séparation des préoccupations tout en évitant la duplication de code et les couplages forts.
La mise en œuvre de la POA n'est pas forcément très compliquée mais elle réclame de penser ou repenser certains « aspects » certaines « préoccupations » pour les implémenter à part du code central de l'application. Ce code sera toujours actif mais il ne se verra pas dans le code principal. Savoir comment découper les aspects traités de cette façon réclame un effort mais les exemples donnés plus haut vous permettent d'imaginer le genre de traitements qui méritent ce type d'attention.
Le code qui va gérer les aspects transversaux peut être implémenté de plusieurs façons selon les outils de développement dont on dispose. Il peut s'agir de préprocesseurs de code comme il en existe en C++, ou à l'inverse de post-processeurs qui vont ajouter du code binaire directement dans le code compilé (comme un virus en quelque sorte). On peut aussi utiliser des compilateurs spéciaux qui savent gérer la POA ou utiliser une stratégie d'interception au moment de l'exécution pour détourner les méthodes et leur ajouter des comportements à la volée.
Dans le Framework .NET c'est plutôt cette dernière option qui sera utilisée (l'interception post-process et injection de code). Un produit comme PostSharp utilise cette technique. Il existe en version basique gratuite et offre des versions payantes plus sophistiquées. L'injection de code utilise pour sa part des frameworks tels que Castle DinamycProxy ou Unity.
Ne vous sauvez pas c'est maintenant que cela devient intéressant !
Le design pattern Décorateur
Décrit par le célèbre « Gang of Four », ce design pattern se définit par l'intention suivante : « Attacher des responsabilités additionnelles à un objet de façon dynamique. ».
Le pattern « decorator » est aussi appeler « wrapper ».
L'une des façons de le représenter sous UML est la suivante :
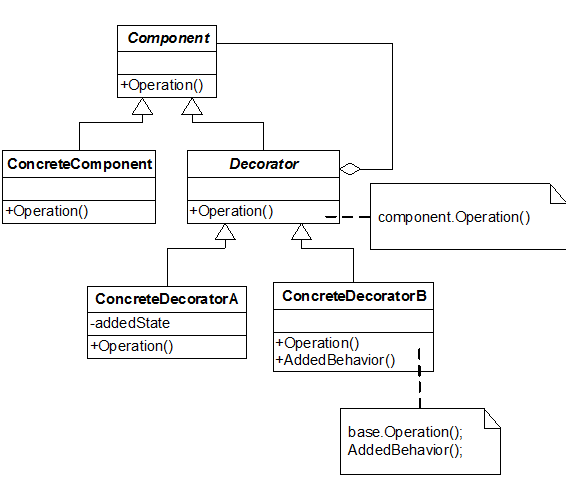
Pour comprendre ce schéma regardons le rôle de chaque participant :
Component
Définit l'interface des objets qui peuvent se voir ajouter des responsabilités dynamiquement.
ConcreteComponent
Définit un objet concret qui supporte l'ajout de responsabilités dynamiquement.
Decorator
Maintient une référence vers une instance de Component et définit une interface qui se conforme à celle de ce dernier.
ConcreteDecorator (A et B)
Implémentations concrète du Decorator qui ajoute effectivement des responsabilités nouvelles à Component.
Il existe des tas de variantes pour représenter ce pattern. On se rappellera l'essentiel : le décorateur « décore » une classe on y ajoutant des comportements, des responsabilités qui n'y sont pas à l'origine et ce sans violer les principes de la POO et sans intervenir sur le code du composant décoré.
Dans le schéma ci-dessus les composants concrets décorés A et B s'utilisent à la place du composant Component, ils fournisseur une interface identique, notamment ils exposent la méthode « Opération() » mais ils ajoutent des comportements à cette opération. Le cas du décorateur concret B est détaillé : on voit qu'il expose Operation() mais qu'il implémente aussi AddedBehavior() et que cette méthode est appelée par Operation(). L'utilisateur croit donc toujours utiliser Component, il n'a pas besoin de modifier son code car l'interface est la même, mais quand il appelle la méthode Operation() elle exécute du code supplémentaire (AddedBehavior()).
Voici un exemple d'implémentation qui suit le schéma présenté :
namespace Structural.Pattern.Decorator
{
class MainApp
{
static void Main()
{
// Create ConcreteComponent and two Decorators
ConcreteComponent c = new ConcreteComponent();
ConcreteDecoratorA d1 = new ConcreteDecoratorA();
ConcreteDecoratorB d2 = new ConcreteDecoratorB();
// Link decorators
d1.SetComponent(c);
d2.SetComponent(d1);
d2.Operation();
// Wait for user
Console.ReadKey();
}
}
/// <summary>
/// The 'Component' abstract class
/// </summary>
abstract class Component
{
public abstract void Operation();
}
/// <summary>
/// The 'ConcreteComponent' class
/// </summary>
class ConcreteComponent : Component
{
public override void Operation()
{
Console.WriteLine("ConcreteComponent.Operation()");
}
}
/// <summary>
/// The 'Decorator' abstract class
/// </summary>
abstract class Decorator : Component
{
protected Component component;
public void SetComponent(Component component)
{
this.component = component;
}
public override void Operation()
{
if (component != null)
{
component.Operation();
}
}
}
/// <summary>
/// The 'ConcreteDecoratorA' class
/// </summary>
class ConcreteDecoratorA : Decorator
{
public override void Operation()
{
base.Operation();
Console.WriteLine("ConcreteDecoratorA.Operation()");
}
}
/// <summary>
/// The 'ConcreteDecoratorB' class
/// </summary>
class ConcreteDecoratorB : Decorator
{
public override void Operation()
{
base.Operation();
AddedBehavior();
Console.WriteLine("ConcreteDecoratorB.Operation()");
}
void AddedBehavior()
{
}
}
}
Un cas plus réel de décoration
Il y a bien entendu milles façons là aussi d'implémenter le pattern et les exigences du monde réel imposent parfois des choses plus « tordues » que cet exemple très scolaire. Ce qu'on peut remarquer c'est que le décorateur ne ré-implémente bien entendu pas le composant concret, il ne fait qu'exposer une interface similaire pour « tromper » les utilisateurs de la classe. En réalité il possède une référence interne sur l'instance de la véritable classe décorée à qui il délègue tous les traitements, une fois qu'il les a manipulé (ajout de code en amont, en aval, filtrages des paramètres, etc).
Pour rendre les choses plus concrètes prenons un exemple C# plus réel même s'il ne s'agit que d'un exemple qui restera simplificateur.
Supposons que nous ayons un Repository, une base de données, un fichier XML, peu importe, et justement nous voulons que cela importe peu. Donc nous allons créer une interface IRepository<T> qui définira les opérations disponibles sur toute classe T pour assurer le stockage et la lecture de ses instances. Les opérations CRUD habituelles se trouveront ainsi définies dans cette interface :
namespace Repository
{
public interface IRepository<T>
{
void Create(T entity);
T Read(int id);
void Update(T entity);
void Delete(T entity);
IEnumerable<T> SelectAll();
}
}
J'ai repris dans l'ordre les opérations « CRUD », c'est-à-dire Create, Read, Update et Delete. J'ai ajouté une opération SelectAll() qui retourne toutes les entités. On notera que pour satisfaire aux exigences de l'acronyme j'ai distordu légèrement le sens de l'implémentation de Create qui devrait s'appeler Add() tel que mon code est écrit.
Nous pouvons désormais écrire des classes réelles d'implémentation de cette interface, l'une pourrait écrire dans un serveur SQL Server, l'autre dans un fichier XML, etc… Ici nous nous contenterons de simuler tout cela par des messages au sein de l'application qui en mode Console (pour éviter tout ce qui pourrait nous écarter de l'essentiel).
Voici une implémentation « a minima » :
public class Repository<T> : IRepository<T>
{
public void Create(T entity)
{
Console.WriteLine("Ajout de {0}",entity);
}
public void Update(T entity)
{
Console.WriteLine("Mise à jour de {0}",entity);
}
public T Read(int id)
{
Console.WriteLine("Lecture entity ID = {0}",id);
return default(T);
}
public void Delete(T entity)
{
Console.WriteLine("Suppression de {0}",entity);
}
public IEnumerable<T> SelectAll()
{
Console.WriteLine("Lister toutes les entités...");
return null;
}
}
Pour utiliser ce joli mécanisme de gestion d'un répertoire d'entités encore nous faut-il des entités à gérer… Nous allons créer une classe « Client » qui servira à cet usage :
public class Client
{
public int Id { get; set; }
public string Entreprise { get; set; }
public string Contact { get; set; }
}
Comme on le constate je ne suis pas allé bien loin… un identifiant et deux propriétés.
Utilisons ce petit ensemble de classes et d'interfaces pour créer un client et effectuer sur celui-ci toutes les opérations offertes par le répertoire :
static void Main(string[] args)
{
var Rep = new Repository<Client>();
var C = new Client
{Id = 5, Entreprise = "E-naxos", Contact = "Olivier Dahan"};
Rep.Create(C);
Rep.Read(5);
Rep.Update(C);
Rep.Delete(C);
Rep.SelectAll();
Console.ReadLine(); // pause
}
Rien de bien fantastique me direz-vous… et vous avez raison nous n'en sommes qu'à la mise en place… Ce qui donne tout de même une sortie console qui ressemble à cela :

Les problèmes commencent…
Tout marche bien, votre application gère des milliers de clients, vous avez créez un répertoire qui gère tout cela avec SQL Server, le code est propre, les couches bien séparées, bref vous êtes un développeur heu-reux ! Et c'est là que votre boss arrive sournoisement dans votre dos (ou votre DSI, ou votre client…) et vous dit : « ah ben oui c'est bien votre truc, mais nous on a besoin que chaque opération soit Loggée dans un fichier au format machin car xxxxx blabla blabla… ».
Et oui… hélas la vraie vie d'un développeur c'est comme ça, et vu qu'il est payé pour, il va bien falloir qu'il s'exécute.
Et il va falloir modifier et ajouter beaucoup de codes même pour notre petit exemple ! Et je vais m'y coller pour vous le faire voir et c'est vraiment parce que je vous aime …
Et nous voici avec une classe qui se présente un peu comme un décorateur mais qui n'est rien d'autre qu'une nouvelle implémentation de l'interface IRepository obtenue à la fois par un méchant copier / coller et par frappe fastidieuse de tous les ajouts… Stricto senso c'est bien un décorateur, mais quel travail pour si peu…
public class LoggedRepository<T> : IRepository<T>
{
private void Log(string msg, object args = null)
{
Console.ForegroundColor=ConsoleColor.Red;
Console.WriteLine(msg,args);
Console.ResetColor();
}
public void Create(T entity)
{
Log("Décorateur - Avant Create {0}",entity);
Console.WriteLine("Ajout de {0}", entity);
Log("Décorateur - Après Create {0}", entity);
}
public void Update(T entity)
{
Log("Décorateur - Avant Update {0}", entity);
Console.WriteLine("Mise à jour de {0}", entity);
Log("Décorateur - Après Update {0}", entity);
}
public T Read(int id)
{
Log("Décorateur - Avant Read {0}", id);
Console.WriteLine("Lecture entity ID = {0}", id);
Log("Décorateur - Après Read {0}", id);
return default(T);
}
public void Delete(T entity)
{
Log("Décorateur - Avant Delete {0}", entity);
Console.WriteLine("Suppression de {0}", entity);
Log("Décorateur - Après Delete {0}", entity);
}
public IEnumerable<T> SelectAll()
{
Log("Décorateur - Avant SelectAll");
Console.WriteLine("Lister toutes les entités...");
Log("Décorateur - Après SelectAll");
return null;
}
}
On peut désormais instancier cette implémentation en place et lieu de la première, le corps du programme ne change pas mais la sortie va être modifiée :
static void Main(string[] args)
{
//var Rep = new Repository<Client>();
var Rep = new LoggedRepository<Client>();
var C = new Client
{Id = 5, Entreprise = "E-naxos", Contact = "Olivier Dahan"};
Rep.Create(C);
Rep.Read(5);
Rep.Update(C);
Rep.Delete(C);
Rep.SelectAll();
Console.ReadLine(); // pause
}
Ce qui donne cette magnifique sortie :
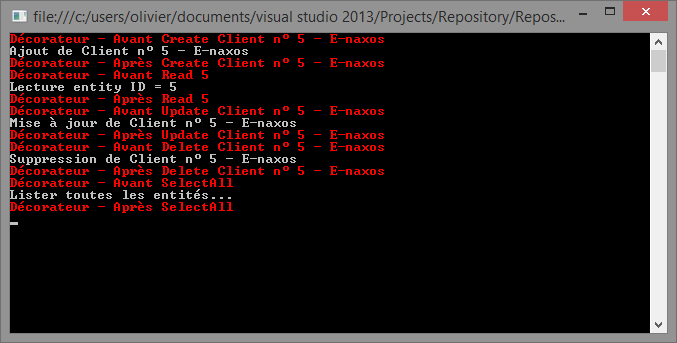
Ça marche, rien à dire…
Notre programme n'est pas modifié et en instanciant habilement le nouveau répertoire avec Log à la place de l'ancien nous avons bien satisfait la demande sans toucher une ligne du programme principal.
C'est bien, mais :
- C'est bourré de code répétitif
- Cela devient difficilement lisible et maintenable
- C'est lourd donc forcément bogué
- C'est hyper désagréable à coder et quand on code sans amour on code mal
C'est alors qu'une petite voix vous susurre à l'oreille « Mais n'y aurait-il pas un moyen plus futé d'arriver au même résultat ? ».
Ecoutez toujours cette petite voix !
Décorer automatiquement
Le rêve ça sera de pouvoir effectuer la même chose mais de façon automatique. On ne sait pas trop encore comment mais un travail si répétitif doit bien pouvoir se « factoriser » d'une façon ou d'une autre, nom d'un informaticien !
Heureusement la réponse est oui, c'est possible de faire mieux et plus automatique. Par exemple le Framework .NET nous offre tout un système dit de Réflexion qui permet d'inspecter les classes, les méthodes et tout le code en général. En utilisant astucieusement cette possibilité nous pourrions décorer automatiquement le premier répertoire pour ajouter les Log en début et fin d'appel de chacune de ses méthodes.
Mais il y a encore mieux…
RealProxy
Je ne sais pour vous mais moi je me demandais quand j'allais y arriver à cette classe présentée dans le texte d'introduction tout là-haut là-haut…
La classe RealProxy se trouve dans l'espace de noms System.Runtime.Remoting.Proxies. C'est une classe abstraite conçue pour être héritée en surchargeant sa méthode Invoke et en ajoutant de nouvelles possibilités (comme le Log de notre exemple).
En partant de notre exemple nous allons créer un proxy dynamique qui va ainsi hériter de RealProxy. Bien entendu dans ce code exemple la quantité de code pour cette implémentation sera peut-être supérieure à la méthode « bête » utilisée juste avant. Mais vous avez compris les avantages qu'on peut tirer d'un système de proxy dynamique et surtout vous savez que le code à décorer d'une application réelle serait autrement plus long que celui de la classe Repository… Et dans ce cas la taille du code du proxy dynamique devient négligeable.
Voici le code du proxy dynamique :
public class DynamicProxy<T> : RealProxy
{
private readonly T _decorated;
public DynamicProxy(T decorated) : base(typeof (T))
{
_decorated = decorated;
}
private void Log(string msg, object args = null)
{
Console.ForegroundColor = ConsoleColor.Red;
Console.WriteLine(msg, args);
Console.ResetColor();
}
public override IMessage Invoke(IMessage msg)
{
var method = msg as IMethodCallMessage;
var methodInfo = method.MethodBase as MethodInfo;
Log("Dynamic Proxy - Avant exécution de {0}",method.MethodName);
try
{
var result = methodInfo.Invoke(_decorated, method.InArgs);
Log("Dynamic Proxy - Après exécution de {0}", method.MethodName);
return new ReturnMessage(result,null,0,method.LogicalCallContext,method);
}
catch (Exception e)
{
Log(string.Format("Dynamic Proxy Error {0} in {1}", e, method.MethodName));
return new ReturnMessage(e,method);
}
}
}
Si vous regardez bien ce code vous verrez que son constructeur appelle le constructeur de la classe décorée. C'est normale puisqu'ici nous ne réécrirons plus le code de cette dernière nous allons le réutiliser et le détourner. Il nous faut donc une instance du vrai code original à décorer.
Ensuite on remarque les fonctions ajoutées, ici seule la méthode Log().
Enfin la méthode Invoke() de RealProxy est surchargée et utilisée pour connaître tout de la méthode qui est en cours d'invocation afin de la modifier selon nos besoins. La modification consiste ici à ajouter un Log() avant et après l'appel de la méthode.
De fait nous n'avons plus besoin de notre classe LoggedRepository puisque nous ré-utiliserons la classe Repository<T> créée au départ.
Hélas, petit détail, nous ne pouvons pas utiliser et appeler notre proxy dynamique directement comme nous l'avons fait pour le LoggedRepository. Tout simplement parce que le proxy dynamique hérite de RealProxy et non pas de IRepository<T> ! Il faut donc trouver une astuce et celle-ci va se concrétiser en une Factory qui saura comment retourner une instance compatible avec notre interface originale.
La factory est assez courte et ressemble à cela :
public class RepositoryFactory
{
public static IRepository<T> Create<T>()
{
var repo = new Repository<T>();
var dinaProx = new DynamicProxy<IRepository<T>>(repo);
return dinaProx.GetTransparentProxy() as IRepository<T>;
}
}
Elle propose une méthode statique permettant de créer le repository. En réalité elle créée bien le proxy dynamique qui lui va créer l'instance du repository… Et par le biais de la méthode GetTransparentProxy elle va retourner l'instance du proxy dynamic sous la forme d'une interface IRepository<T>. L'astuce est bien trouvée non ?
De fait notre proxy dynamique et sa factory vont s'utiliser comme suit dans notre programme dont le corps rappelons-le n'a pas bougé d'un pouce depuis le début de nos expérimentations…
static void Main(string[] args)
{
//var Rep = new Repository<Client>();
//var Rep = new LoggedRepository<Client>();
var Rep = RepositoryFactory.Create<Client>();
var C = new Client
{Id = 5, Entreprise = "E-naxos", Contact = "Olivier Dahan"};
Rep.Create(C);
Rep.Read(5);
Rep.Update(C);
Rep.Delete(C);
Rep.SelectAll();
Console.ReadLine(); // pause
}
En commentaire nous voyons les deux étapes précédentes, ce sont les seules choses qui ont changé dans notre code, il faut s'imaginer que le corps principal est en réalité un énorme bloc de type DAL ou BOL et qu'il n'a pas été modifié d'une virgule. Pourtant il satisfait maintenant des exigences nouvelles qui pourront être modifiées à nouveau, augmentées, et tout cela sans réécrire.
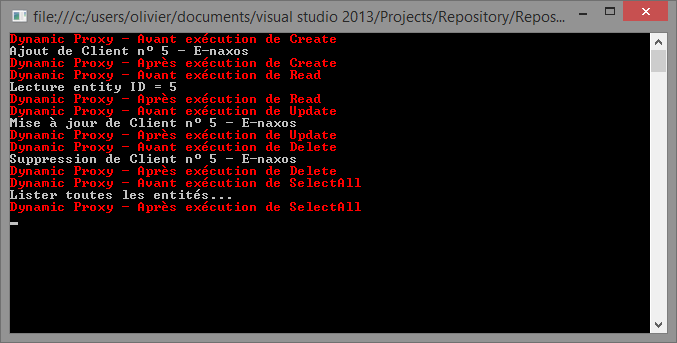
Le run de la dernière version qui fonctionne avec RealProxy donne :
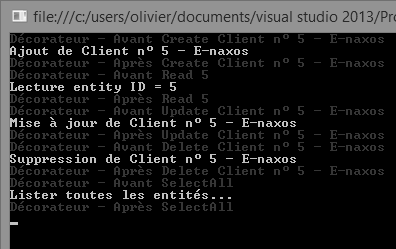
Pour comparaison voici le run de la version pattern Decorator (à gauche) et la version RealProxy (à droite ou en dessous selon la disposition finale dans la page du blog…) :
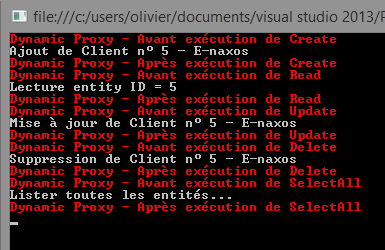
Conclusion
La classe RealProxy est une grande inconnue du Framework .NET à un tel point que rares sont les exemples la mettant en œuvre. Pourtant elle permet de travailler dans un mode proche de la programmation Orientée Aspects mais surtout, car on se fiche un peu de l'académisme ce qui nous intéresse c'est le concret, elle permet de se sortir de mauvaises passes en autorisant l'ajout de nouvelles fonctions à une application sans toucher ni déstabiliser le code de celle-ci.
Rien n'est jamais parfait, la version « pattern Decorator » bien que « moche » lourde et répétitive est en réalité bien plus efficace en termes de performances. RealProxy utilise la Réflexion qui, on le sait, ralentit un peu l'exécution du code.
Toutefois ce point n'est que rarement important dans une application de gestion classique, les PC modernes tournent largement assez vite pour que cela soit l'UC qui passe 95% de son temps à attendre plutôt que l'utilisateur… perdre quelques millisecondes pour l'ajout propre et maintenable de nouvelles fonctionnalités à un programme est un coût ridicule.
Pour une application temps critique, un jeu, je ne dis pas que cela sera sans conséquences, mais en dehors de ces cas particuliers RealProxy vous rendra d'immenses services.
On pourrait d'ailleurs continuer sur la base de l'exemple donné en filtrant les méthodes selon les droits de l'utilisateur. Un Admin pourra détruire une entité un simple utilisateur ne le pourra pas, c'est facile à faire, il suffit de se baser sur le nom de la méthode par exemple. On peut aussi utiliser la stratégie des attributs custom et décorer son code d'attributs qui seront ensuite pris en compte par un montage de type RealProxy.
Gérer après coup la sécurisation des appels à un service WCF peut aussi faire partie des choses que RealProxy vous aidera à réaliser mille fois plus vite et plus proprement.
Il y a des millions de possibilités de bien utiliser RealProxy dans la vie réelle, celle où les spécifications évoluent et où on doit conserver coute que coute un code maintenable ni perdre des années à tout réécrire.
Pensez-y ! …. Et Stay Tuned !
Repository.zip (45,35 kb)