[new:31/12/2013]Troisième Tome mis en ligne, la série ALL DOT.BLOG continue. Aujourd’hui plus de 100 pages sur LINQ, Entity Framework et un peu de RIA Services.Plus...
[new:31/01/2011]WCF Ria Services est une mécanique de précision. En démo tout est toujours simple et évident, dans la réalité on rencontre toujours quelques cas plus retors et pas forcément dans des features ultra sophistiquées... Par exemple le chargement d’entités associées réclame de connaitre la double astuce que je vais vous présenter.Plus...
[new:05/07/2010]Vous possédez un OS récent, comme Windows 7, vous développez avec les outils les plus modernes (disons VS 2010 au hasard) et, bien entendu votre base de données installée en local est SQL Server 2008. D’une part parce que c’est une bonne version, mais surtout parce que vous n’avez pas trop le choix… Vous créez une application pour un client qui utilise SQL Server 2005 et là, pof! dès qu’il exécute votre logiciel il y a une exception du genre “The version of SQL Server in use does not support datatype 'datetime2”… Plus...
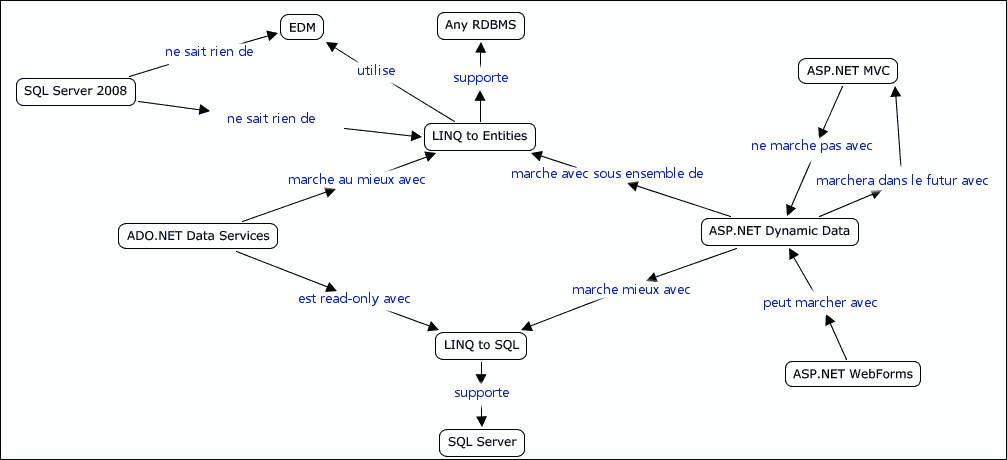
Depuis la sortie de .NET Microsoft n'arrête plus sa course folle ! La plupart des technologies publiées faisaient partie d'un plan presque totalement connu à l'avance, comme WPF, WCF etc. Il a fallu du temps pour qu'émerge ses "modules" de .NET car même le plus puissant des éditeurs de logiciels du monde ne peut pas releaser la totalité d'une montagne comme .NET en un seul morceau. S'il était clair que WPF serait la nouvelle gestion des interfaces utilisateurs et que Windows Forms n'était qu'un "os à ronger" en attendant, le foisonnement des technologies tournant autour des données n'était pas forcément visible ni prévisible il y a quelques années. Et même aujourd'hui savoir ce qui existe et comment s'en servir avec l'ensemble des autres technologies n'est pas forcément une mince affaire !
Un petit dessin valant tous les discours, voici un diagramme qui tourne sur les blogs américains de Microsoft et que j'ai en partie traduit pour vous, en espérant que cela vous aidera à y voir plus clair !
Quelques précisions pour certains acronymes ou noms de technologies :
[Faite un clic-droit sur l'image et copiez-la pour l'afficher en 100% dans Word ou autre ]
Stefan Cruysberghs a publié (en anglais) une série de trois articles (récents) sur l'Entity Framework qui proposent un tour d'horizon assez intéressant de cette technologie.Plus...