Il faut bien se détendre un peu... Et que fait un geek pour se détendre ? Il allume son PC (en fait il ne l'éteint jamais !). Alors pour me changer les idées, je me suis mis en tête d'installer MONO pour "voir" où le projet en est. C'est cette petite aventure que je m'en vais vous conter, ça pourra vous servir...
Mais voilà, avant de jouer avec C# sous Linux il faut d'abord installer Linux (hmmm), choisir l'une de ses distribs et surtout arriver à le faire marcher ! Et comme je suis pervers mais pas fou, hors de question de faire un dual boot (j'en ai déjà un XP/Vista) ni même de reformater l'une de mes machines. Il va donc falloir virtualiser...
Abonné MSDN je dispose de tout plein de softs de Microsoft, dont Virtual PC 2007. J'ai commencé petit joueur par une Mandriva. Impossible à installer, le fameux problème d'écran 24 bits par défaut de Linux... Une vraie cata. J'ai passé des heures à chercher sur le Web, on trouve des trucs, mais aucun ne marche !
Après des heures à tourner en rond face à un écran très élargi et illisible, j'ai renoncé. J'ai donc laissé Virtual PC de côté, super chouette pour virtualiser du DOS, de l'XP ou du Vista, mais visiblement pas très open à Linux...
En farfouinant je suis tombé sur un virtualiseur gratuit écrit par l'ennemi juré de Microsoft, Sun. Du coup j'ai pas essayé de voir si leur machin savait lui gérer la virtualisation de Windows aussi mal que Virtual PC gère mal Linux, mais pour virtualiser du Linux ça semblait un bon choix. J'ai donc télécharger VirtualBox. Ca s'installe facilement, ça fait ce que ça dit et ça marche plutôt vite. Un bon point pour ce produit gratuit.
J'entreprends alors de virtualiser mon Mandriva que je n'avais pu installer sous Virtual PC. Et là, surprise, ça passe facile. Mon coeur s'emplit de joie en voyant Linux tourner dans une fenêtre... Mandriva, hélas, c'est KDE. L'avantage de KDE c'est d'être un clône de Windows XP niveau interface. On s'y retrouve facilement. Mais voilà, je n'y avais pas pensé avant, le kit de développement de MONO réclame visiblement GNOME ! Zut! me suis-je exclamé après toutes ses heures (en réalité c'était pas "zut", mais un truc du même genre en plus .. illustré :-) ). [EDIT:] Il semble que le site de MONO ignore Mandriva, mais depuis le gestionnaire de logiciels de ce dernier on peut accéder au téléchargement de MONO et des outils de développement. Je viens de le faire et oui, ça marche parfaitement. On peut donc utiliser Mandriva sans problème [/EDIT]. [EDIT2:] Comme je suis une quiche sous Linux, je n'avais pas pigé non plus que Mandriva permet de changer de bureau et de système d'affichage. On peut donc être en KDE ou GNOME sans problème la non plus. C'est en bûchant qu'on devient bucheron n'est-il pas... [/EDIT2]
Je farfouine à nouveau... et au final je me décide pour OpenSuse, promu par Novell qui se trouve derrière MONO aussi, ça devrait matcher. Bonne pioche ! Je prend la 11.0 mais ils préviennent que les fichiers de plus 4 Go posent des problèmes en téléchargement HTTP depuis Internet Explorer. J'avais téléchargé des DVD ISO il y a peu de temps avec IE sans problème et je me doutais bien qu'il s'agissait là de médisances de concurrents, mais par précaution j'ai pris l'option téléchargement par Torrent. Deux ou trois heures après j'avais mon ISO.
...Et on est reparti pour la création d'une machine virtuelle. Au passage je me dis, tiens, pourquoi ne pas redonner sa chance à Virtual PC, après tout. Je vous passe les détails, une heure de perdue pour exactement le même problème sans arriver à trouver une solution. Retour à VirtualBox.
Là les choses se passent comme avec Mandriva, c'est à dire bien et facilement.
Installation de OpenSuse. C'est pas mal. J'arrive ensuite à faire marcher l'installeur YaST pour ajouter les références au projet Mono et à installer l'ensemble des paquets.
Cool. J'ai maintenant un joli OpenSuse avec MONO et l'environnement de développement ! Je fais un nouveau projet console et je tape deux ou trois truc pour voir. Pas mal. C'est du niveau C# 2.0 avec les génériques. Je n'ai pas encore creusé plus loin, mais voir mon petit programme s'animer dans une fenêtre Linux sur mon XP, ça fait plaisir...
J'ai voulu aller un peu plus loin en partageant un disque physique de ma machine avec la machine virtuelle. VirtualBox le permet en installant des extensions. Retour à la galère, il faut les sources du noyau, le make et GCC. Trouver ces merveilles, les placer dans YaST et les installer s'est révélé moins dur que je le pensais. Mais la fameuse extension de VirtualBox n'a jamais voulu s'installer... C'est un script (.run) et quand je double cliquait dessus il me disait que j'avais pas les privilège admin ce qui plantait le script visiblement. Pourtant le compte que je me suis créé est dans le group des admins... Mystère de Linux. En changeant de user et en me loggant comme "root" c'est allé un cran plus loin. Mais là c'est un autre problème un peu confus que je n'ai pas pu résoudre qui s'est pointé... VirtualBox et ses extensions ne sont donc pas trop au point si on veut utiliser toutes les astuces. [EDIT] Devant l'impossibilité de partager un disque XP avec la VM j'ai essayé de faire un partage réseau... Mandriva ou OpenSus voient le réseau et Internet, mais malgré tous mes efforts à ce jour, impossible de leur faire voir les autres machines du réseau et encore moins leurs disques, malgré le daemon Lisa, malgré Samba et autres pares-feux aux configurations ésotériques... Si quelqu'un sait... laissez un commentaire![/EDIT]
Conclusion
Les leçons à tirer sont les suivantes : Il faut utilise VirtualBox et non Virtual PC si on veut virtualiser du Linux, Il faut prendre une distrib Linux compatible avec Mono, OpenSuse semble parfaite pour ça [EDIT] Mandriva va très bien aussi [/EDIT]. Sinon pour le reste ça s'installe correctement, YaST simplifiant les choses (mais il faut comprendre comment marche YaST, notamment l'ajout d'une source d'installation, c'est là l'astuce !).
Les dernières moutures de Linux, Suse ou Mandriva sont des pâles copies de Windows XP, en moins chouette visuellement, et en plus complexe à faire marcher. Esthétiquement ça fait un peu Matrix, parfois l'interface graphique disparaît (lancement et extinction par exemple) et on voit des trucs défilés dans une console, très geek mais pas très "end user" donc. Toutefois il faut saluer les gros efforts de ces dernières années pour rendre Linux utilisable, mais on l'impression d'un truc "cheap", on voit bien que c'est gratuit quoi... Surtout quand on utilise Vista, dont on peut dire ce qu'on veut, mais quand on en a pris l'habitude, c'est autrement plus joli et plus agréable que XP ou les distribs Linux. Les fous de la customisations diront qu'ils peuvent installer des bureaux super chouettes sous Linux, c'est vrai. Mais que d'effort pour arriver à faire, de façon compliquée, ce qu'un Vista fait de base de façon simple... Reste que la concurrence Linux est une bonne chose, et les essais que je vous conte ici sont la preuve que j'attache de l'importance à cette alternative même si elle est loin de me convaincre, pour le moment, de reformater toutes mes machines sous Linux.
Mais bon, le truc ce n'était pas de tester Linux ni de donner mon avis sur la question, Linux est un monde fermé, si un "vendu" à la cause Microsoft fait des réserves c'est forcément qu'il est corrompu et donc que son avis n'a pas d'intérêt. Les Linuxiens ne lisent donc de toute façon pas les avis des non linuxiens sur Linux. Non, mon but était d'installer MONO et de faire des tests. De ce côté là c'est concluant. Juste une chose qu'il me reste à creuser, la gestion des fenêtres (l'équilavent de Windows Forms) en tout cas dans la version dont je dispose, utilise un truc vraiment très différent donc pas portable du tout. Il va falloir que je regarde s'il existe une émulation des Windows Forms sinon cela limite la compatibilité entre .NET et MONO aux libs de classes. C'est déjà pas mal, mais ça me semble trop juste. [Edit:] Il y a bien un System.Windows.Forms dans les libs installées, mais point de designer dans l'IDE.. Il semble qu'il en existe un, mais j'ai pas tout pigé comment l'obtenir, est ce un truc à part, un plugin, en tout cas ça demande d'obtenir le source de MONO par svn et de tout recompiler.. Brrr. L'esprit Linux c'est, il faut l'avouer, très très éloigné des "user experiences" de MS ! [/Edit]
Voilà pour cette petite histoire, qui, au fil des paragraphes vous aura peut-être donné l'envie de tenter l'expérience aussi, en utilisant directement les bonnes solutions et sans perdre de temps :-)
avant de lâcher mon traditionnel "Stay Tuned!" voici une petite image, ça fait toujours plaisir :
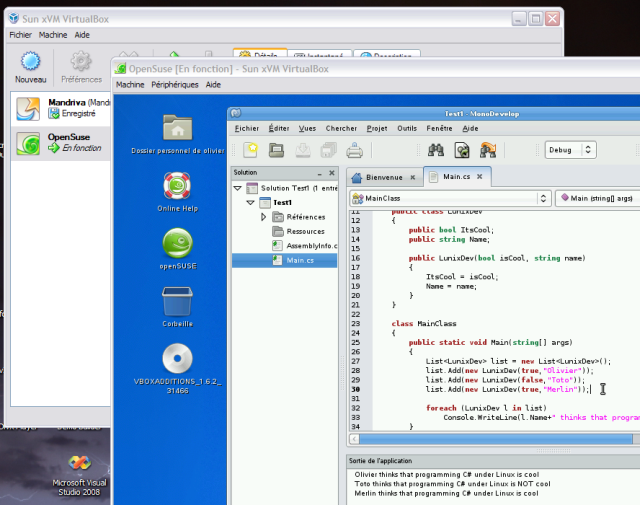
OpenSuse 11.0 avec MonoDevelop
Sous les pavés la plage... Chez moi c'est vrai, mais en plus sous la fenêtre OpenSuse il y a aussi le bureau XP avec VirtualBox (et l'icone de lancement de VS 2008 mon compagnon de tous les jours) ! Cool isn't it ?
Alors... pour d'autres aventures : Stay Tuned !
[EDIT:] Comme j'ai réussi à faire pareil sous Mandriva, une petite image aussi ![/EDIT]